Train a Smart Answers Supervised Model
Train a Smart Answers Supervised Model
The Supervised solution for Smart Answers begins with training a model using your existing data and the Smart Answers Supervised Training job, as explained in this topic. The job includes an auto-tune feature that you can use instead of manually tuning the configuration.
Training job requirements
Storage150GB plus 2.5 times the total input data size.Processor and memoryThe memory requirements depend on whether you choose GPU or CPU processing:| GPU | CPU |
|---|---|
|
|
Prepare the input data
-
Format your input data as question/answer pairs, that is, a query and its corresponding response in each row.
You can do this in any format that Managed Fusion supports.
If there are multiple possible answers for a unique question, then repeat the questions and put the pair into different rows to make sure each row has one question and one answer, as in the example JSON below:
-
Index the input data in Managed Fusion.
If you wish to have the training data in Managed Fusion, index it into a separate collection for training data such as
model_training_input. Otherwise you can use it directly from the cloud storage.
Configure the training job
- In Managed Fusion, navigate to Collections > Jobs.
-
Select Add > Smart Answers Supervised Training:
-
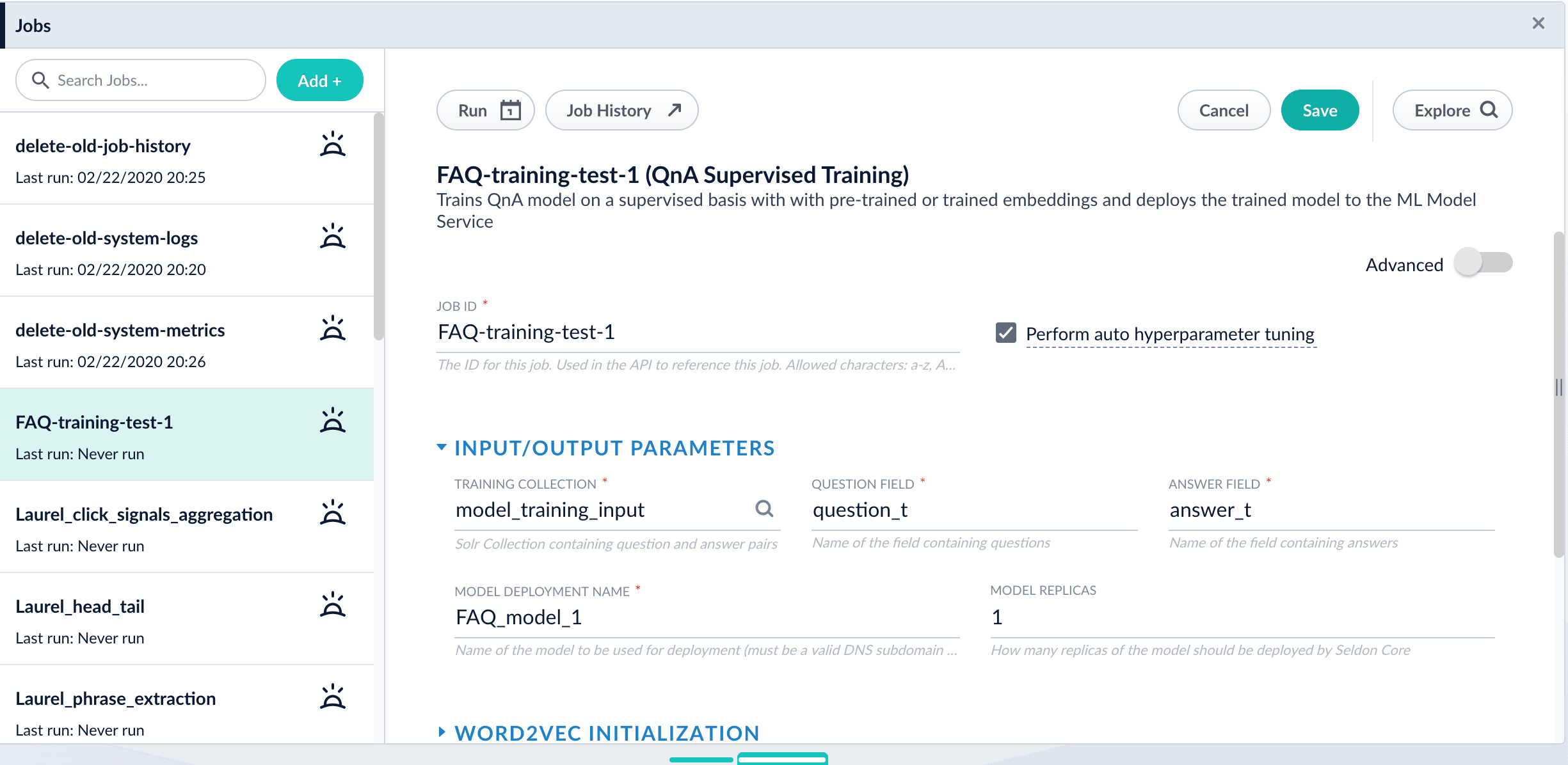
In the Training Collection field, specify the input data collection that you created when you prepared the input data.
You can also configure this job to read from or write to cloud storage.
- Enter the names of the Question Field and the Answer Field in the training collection.
- Enter a Model Deployment Name. The new machine learning model will be saved in the blob store with this name. You will reference it later when you configure your pipelines.
-
Configure the Model base.
There are several pre-trained word and BPE embeddings for different languages, as well as a few pre-trained BERT models.
If you want to train custom embeddings, select
word_customorbpe_custom. This trains Word2vec on the provided data and specified fields. It might be useful in cases when your content includes unusual or domain-specific vocabulary. If you have content in addition to the query/response pairs that can be used to train the model, then specify it in the Texts Data Path. When you use the pre-trained embeddings, the log shows the percentage of processed vocabulary words. If this value is high, then try using custom embeddings. The job trains a few (configurable) RNN layers on top of word embeddings or fine-tunes a BERT model on the provided training data. The result model uses an attention mechanism to average word embeddings to obtain the final single dense vector for the content. - Optional: Check Perform auto hyperparameter tuning to use auto-tune. Although training module tries to select the most optimal default parameters based on the training data statistics, auto-tune can extend it by automatically finding even better training configuration through hyper-parameter search. Although this is a resource-intensive operation, it can be useful to identify the best possible RNN-based configuration. Transformer-based models like BERT are not used during auto hyperparameter tuning as they usually perform better yet they are much more expensive on both training and inference time.
-
Click Save.
 If using solr as the training data source ensure that the source collection contains the
If using solr as the training data source ensure that the source collection contains therandom_*dynamic field defined in itsmanaged-schema.xml. This field is required for sampling the data. If it is not present, add the following entry to themanaged-schema.xmlalongside other dynamic fields<dynamicField name="random_*" type="random"/>and <fieldType class=“solr.RandomSortField” indexed=“true” name=“random”/> alongside other field types. - Click Run > Start.
Next steps
- See A Smart Answers Supervised Job’s Status and Output
- Configure The Smart Answers Pipelines
- Evaluate a Smart Answers Query Pipeline