The NLP Annotator index stage performs Natural Language Processing tasks. You can choose from different NLP libraries, either OpenNLP or the JohnSnow Lab library, which runs on Spark. Note: Only the pre-trained NER model is supported. If choosing an NER model, download NerDLModel instead of NerCRFModel. The NLP Annotator supports the following tasks:Documentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
-
If choosing JohnSnow Lab (recommended for large dataset processing):
-
NER (Name Entity Recognition)
Fusion AI uses the deep learning pre-trained NER model that JohnSnowLab provides. Currently, the pre-trained extraction model covers the following name entities:
- ORG (organization)
- PER (person)
- LOC (location)
- Sentence detection
- POS(Part of Speech) Tagging
-
NER (Name Entity Recognition)
Fusion AI uses the deep learning pre-trained NER model that JohnSnowLab provides. Currently, the pre-trained extraction model covers the following name entities:
-
If choosing OpenNLP:
- NER
- Sentence detection
- POS Tagging
- Shallow Parsing (Chunking)
-
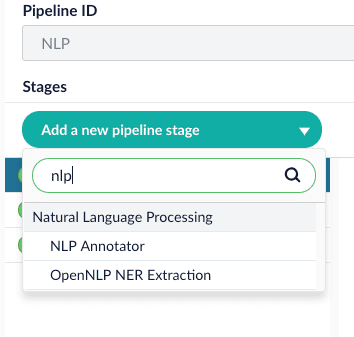
Add NLP Annotator index stage.
-
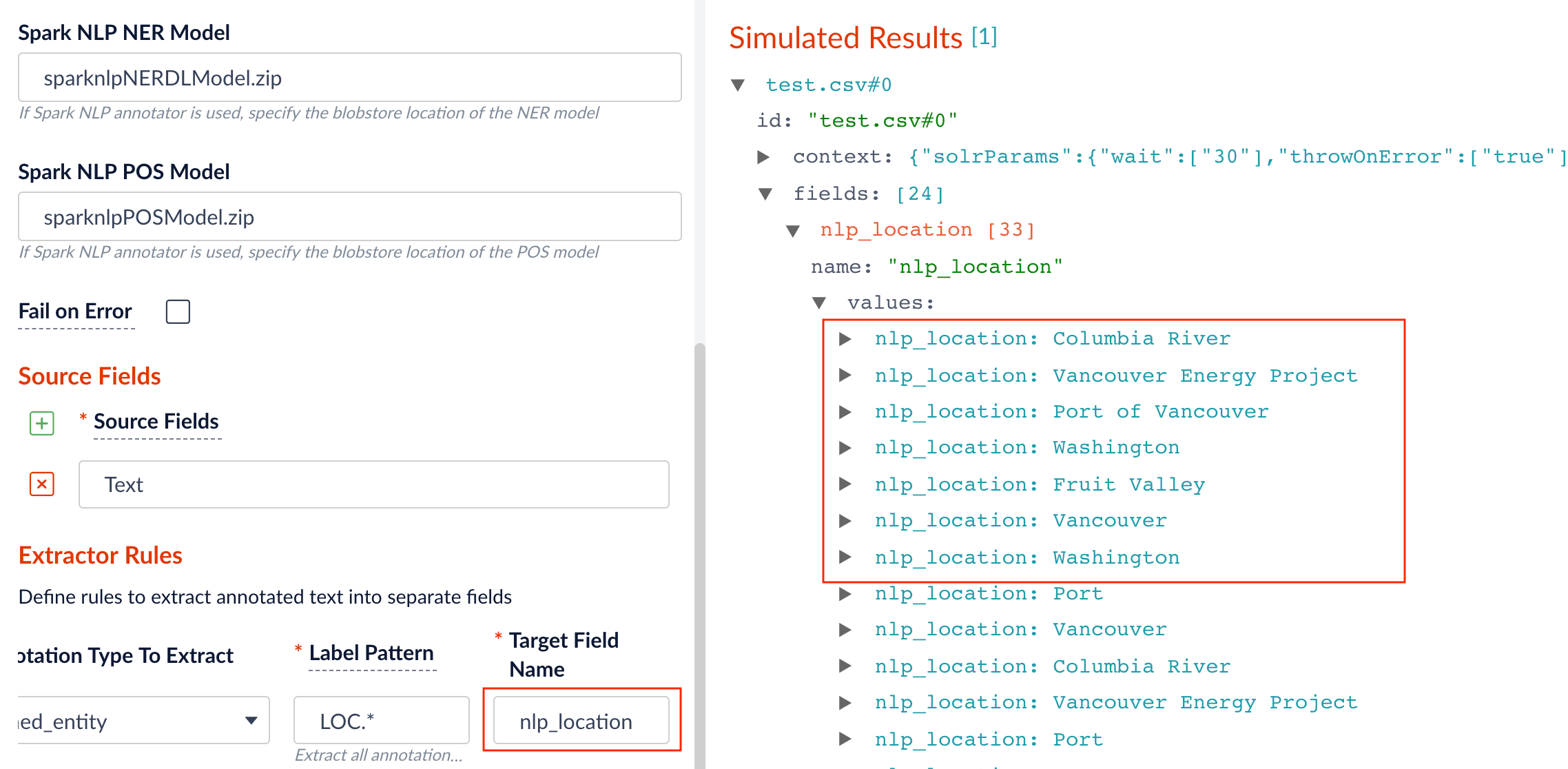
Choose the annotator type (OpenNLP or SparkNLP).

sparknlp model, you need to download and install one or more models:
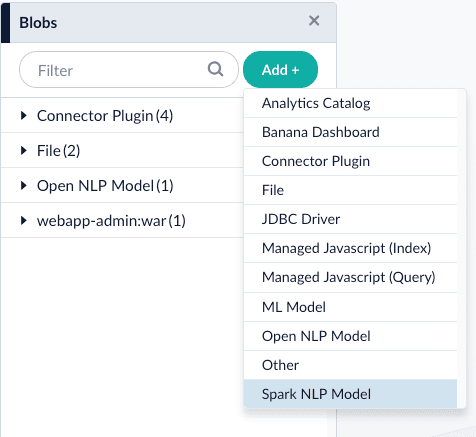
.. Download the models at https://github.com/JohnSnowLabs/spark-nlp#models.
.. Rename the downloaded models to something easy to identify, then upload them to Fusion’s blob store.
-
Specify the model to use (fill the box with
model idin the blob store).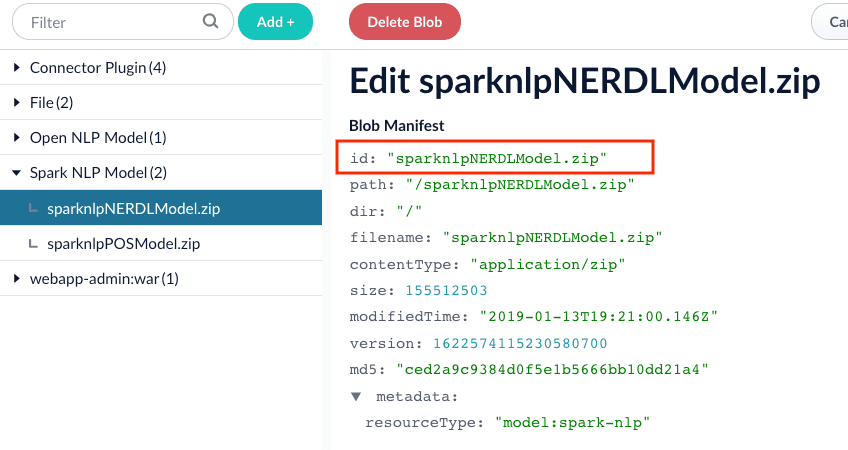

-
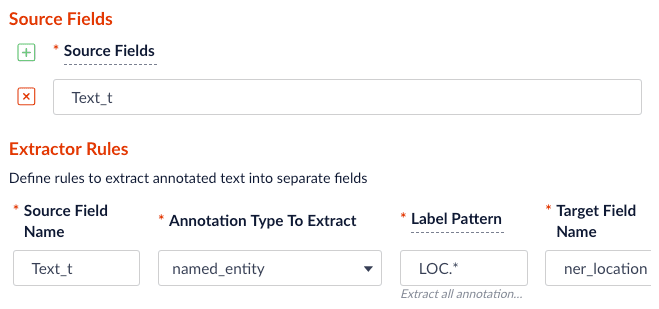
Specify the source, label pattern, and target (destination) fields:
- source field: the raw text with name entities to be extracted.
- label pattern: regex pattern that matches the NER/POS labels: for example,
PER.will match extracted name entities with labelPERSON, whileNN.will match tagged nouns. - target field: the outcome extraction/tagging and so on.