{description &&
{formatDescription(description)}
}
{visibleProps.map(([name, prop]) => {
const isRequired = requiredProps.includes(name);
const hasDefault = prop.default !== undefined;
const rawDefault = prop.default;
const isComplexDefault = hasDefault && (typeof rawDefault === "object" || typeof rawDefault === "string" && (rawDefault.length > 20 || rawDefault.includes('"')));
const fieldProps = {
key: name,
body: prop.title || name,
type: prop.type,
...prop.title && ({
post: [<>
API property: {name}]
}),
...isRequired && ({
required: true
}),
...!isComplexDefault && hasDefault ? {
default: sanitize(String(rawDefault))
} : {}
};
const isObject = prop.type === "object" && prop.properties;
const isArrayOfObjects = prop.type === "array" && prop.items?.type === "object" && prop.items.properties;
return
{prop.description && {formatDescription(prop.description)}
}
{isComplexDefault &&
Default:
{JSON.stringify(rawDefault, null, 2)}
}
{isArrayOfObjects &&
Object attributes:
{'{\n'}
{Object.entries(prop.items.properties).map(([iname, iprop]) => <>
{` ${iname}`}
{prop.items?.required?.includes(iname) && required}
{`: {\n display name: ${sanitize(iprop.title || '')}\n type: ${iprop.type}\n }\n`}
)}
{'}'}
}
{isObject &&
}
;
})}
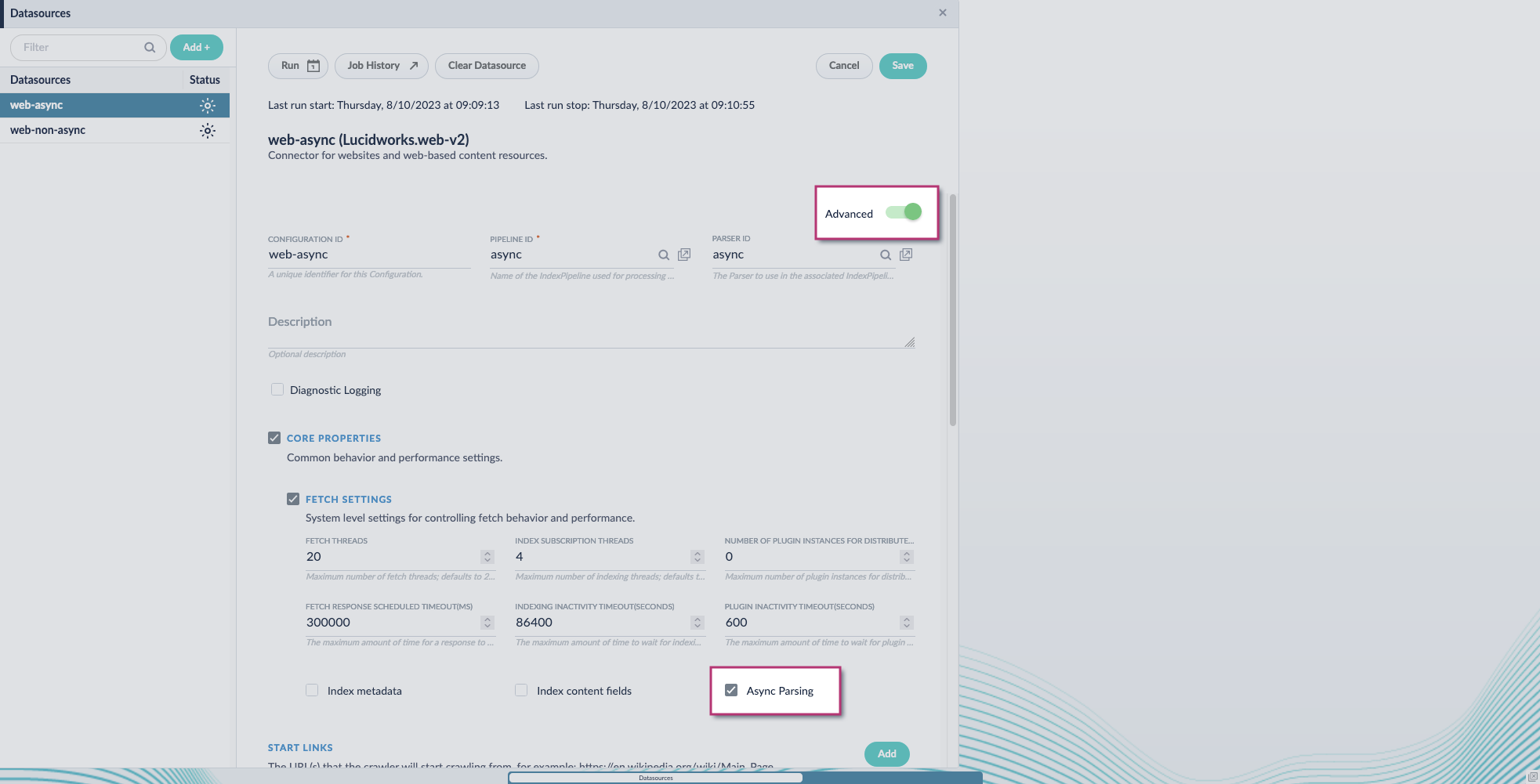
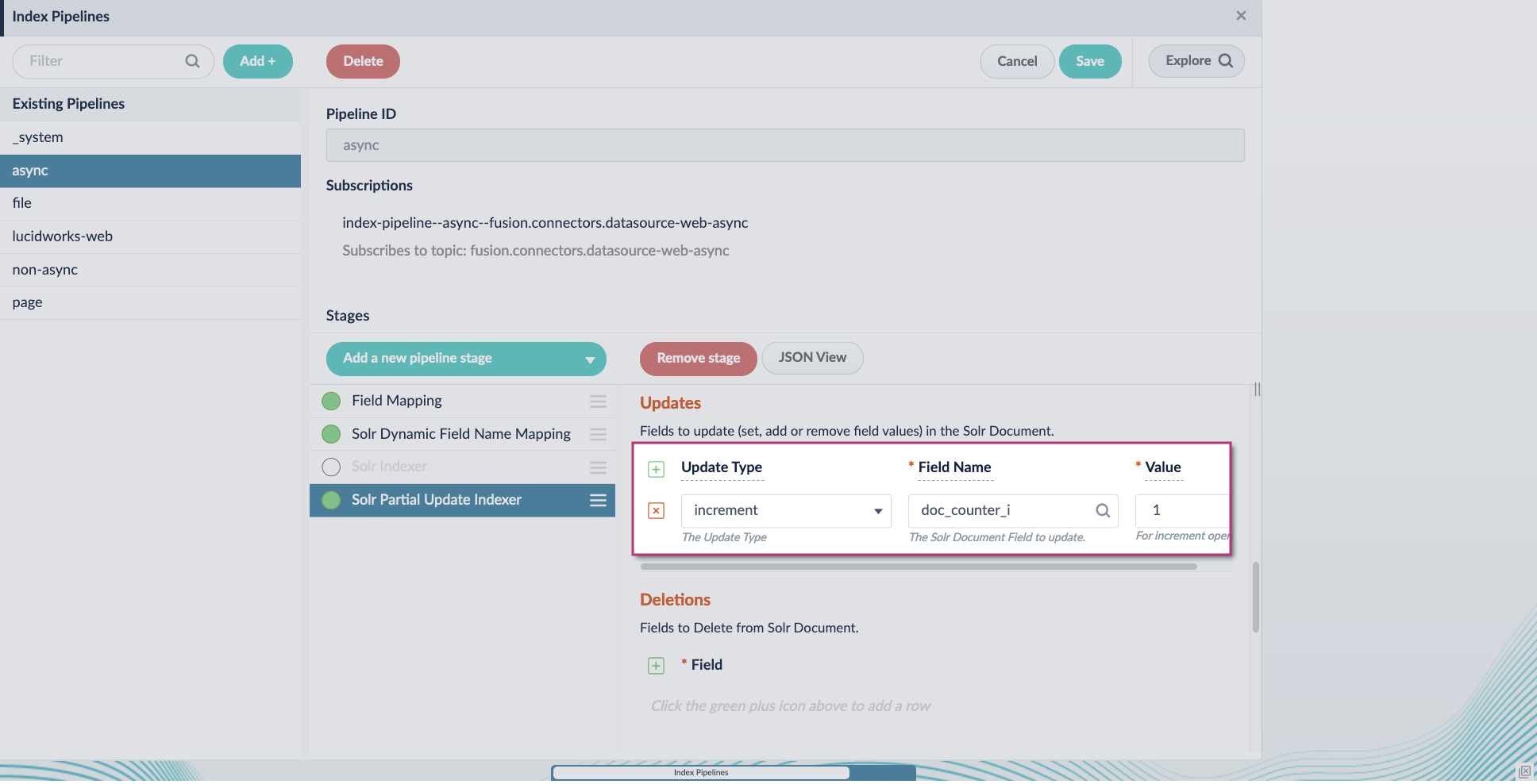
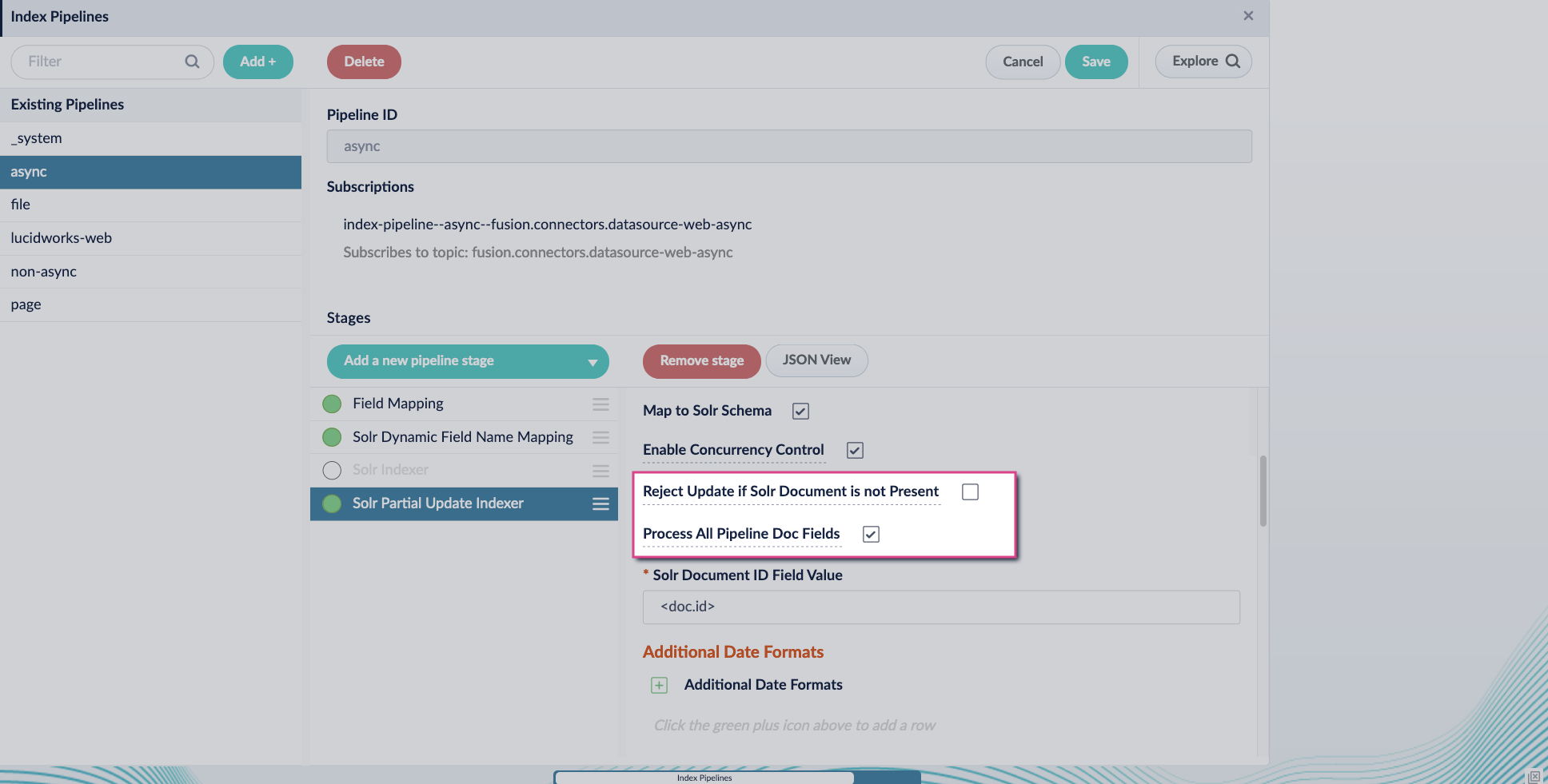 4. Include an extra update field in the stage configuration using any update type and field name. In this example, an incremental field `docs_counter_i` with an increment value of `1` is added:
4. Include an extra update field in the stage configuration using any update type and field name. In this example, an incremental field `docs_counter_i` with an increment value of `1` is added:
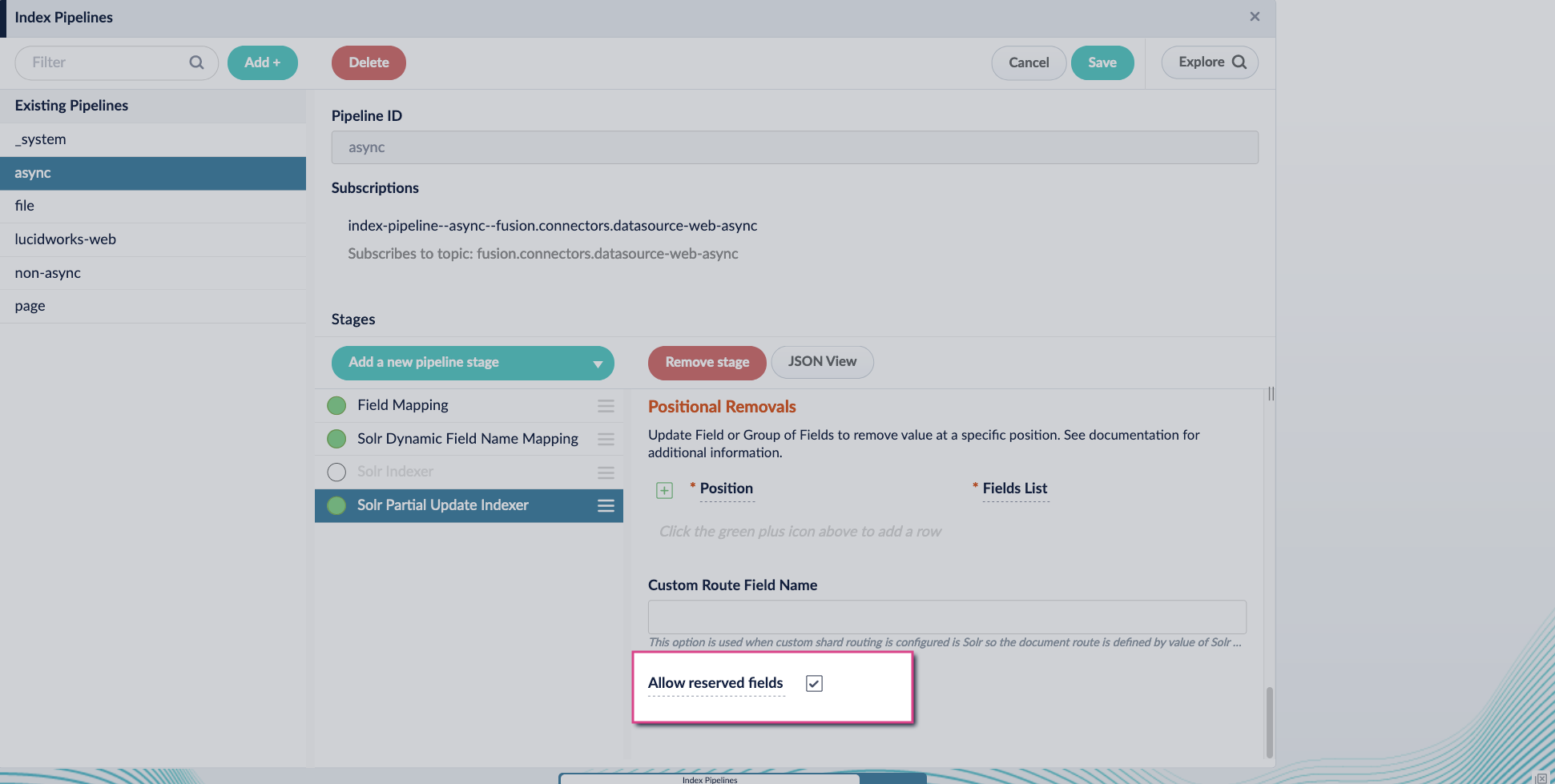
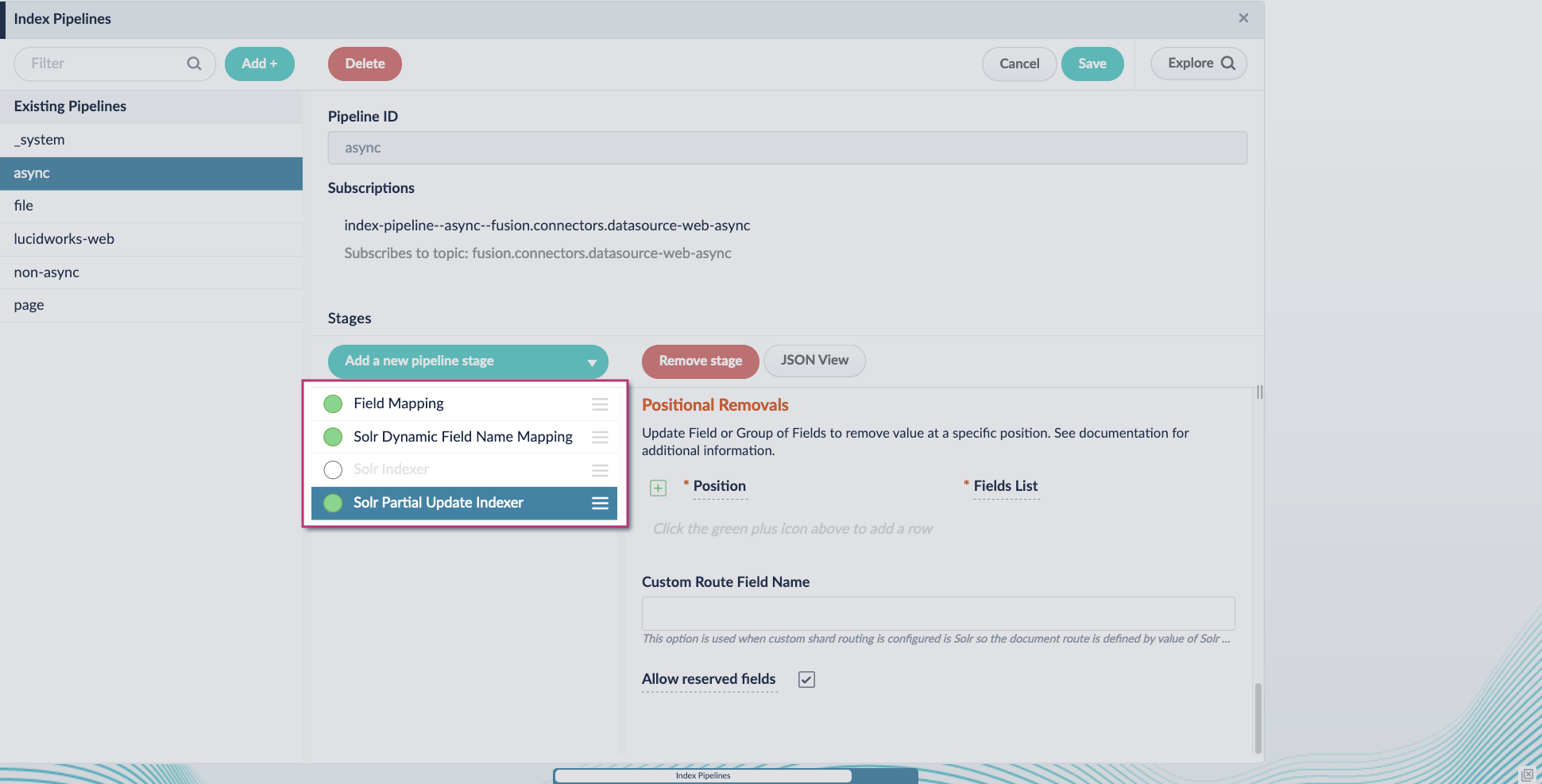
 5. Enable the **Allow reserved fields** option:
5. Enable the **Allow reserved fields** option:
 6. Click **Save**.
7. Turn off or remove the **Solr Indexer stage**, and move the **Solr Partial Update Indexer stage** to be the last stage in the pipeline.
6. Click **Save**.
7. Turn off or remove the **Solr Indexer stage**, and move the **Solr Partial Update Indexer stage** to be the last stage in the pipeline.
 Asynchronous Tika parsing setup is now complete. Run the datasource indexing job and monitor the results.
Asynchronous Tika parsing setup is now complete. Run the datasource indexing job and monitor the results.