{description &&
{formatDescription(description)}
}
{visibleProps.map(([name, prop]) => {
const isRequired = requiredProps.includes(name);
const hasDefault = prop.default !== undefined;
const rawDefault = prop.default;
const isComplexDefault = hasDefault && (typeof rawDefault === "object" || typeof rawDefault === "string" && (rawDefault.length > 20 || rawDefault.includes('"')));
const fieldProps = {
key: name,
body: prop.title || name,
type: prop.type,
...prop.title && ({
post: [<>
API property: {name}]
}),
...isRequired && ({
required: true
}),
...!isComplexDefault && hasDefault ? {
default: sanitize(String(rawDefault))
} : {}
};
const isObject = prop.type === "object" && prop.properties;
const isArrayOfObjects = prop.type === "array" && prop.items?.type === "object" && prop.items.properties;
return
{prop.description && {formatDescription(prop.description)}
}
{isComplexDefault &&
Default:
{JSON.stringify(rawDefault, null, 2)}
}
{isArrayOfObjects &&
Object attributes:
{'{\n'}
{Object.entries(prop.items.properties).map(([iname, iprop]) => <>
{` ${iname}`}
{prop.items?.required?.includes(iname) && required}
{`: {\n display name: ${sanitize(iprop.title || '')}\n type: ${iprop.type}\n }\n`}
)}
{'}'}
}
{isObject &&
}
;
})}
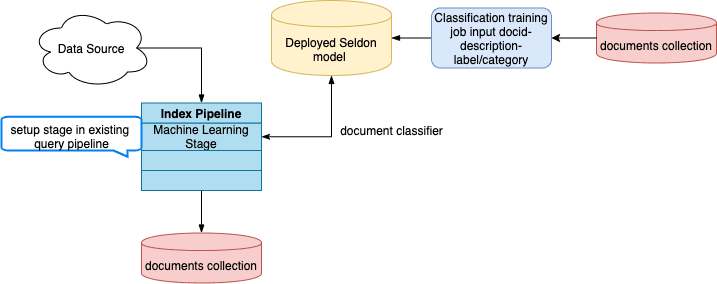
 See the detailed steps below.
## To predict the categories of new queries
1. Navigate to **Collections** > **Jobs** > **Add+** > **Build Training Data** to create a new Build Training Data job.
2. Configure the job as follows:
1. In the **Catalog Path** field, enter the collection name or cloud storage path where your main content is stored.
2. In the **Catalog Format** field, enter `solr` if you are analyzing a Solr collection, or another format if your content is in the cloud.
3. In the **Signals Path** field, enter the collection name or cloud storage path where your signals data is stored.
4. In the **Output Path** field, enter the collection name or cloud storage path where you want to store the training data.
5. In the **Category Field in Catalog** field, enter the field name for the category data in your main content.
6. In the **Item ID Field in Catalog** field, enter the field name for the item IDs in your main content.
7. Check that the values of **Item ID Field in Signals** and **Count Field in Signals** match the field names in your signals data.
3. Save the job.
4. Click **Run** > **Start** to run the job.
5. Navigate to **Collections** > **Jobs** > **Add+** > **Classification** to create a new Classification job.
6. Configure the job as follows:
1. In the **Model Deployment Name** field, enter an ID for the new classification model.
2. In the **Training Data Path** field, enter the collection name or cloud storage path from the Build Training Data job’s **Output Path** field.
3. In the **Training Data Format** field, leave the default `solr` value if the **Training Data Path** is a collection or if you used the default format in your Build Training Data job configuration. If you configured the Build Training Data job to output a different format, enter it here.
4. In the **Training collection content field**, enter `query_s`, the default content field name in the Build Training Data job’s output.
5. In the **Training collection class field**, enter `category_s`, the default category field name in the Build Training Data job’s output.
See the detailed steps below.
## To predict the categories of new queries
1. Navigate to **Collections** > **Jobs** > **Add+** > **Build Training Data** to create a new Build Training Data job.
2. Configure the job as follows:
1. In the **Catalog Path** field, enter the collection name or cloud storage path where your main content is stored.
2. In the **Catalog Format** field, enter `solr` if you are analyzing a Solr collection, or another format if your content is in the cloud.
3. In the **Signals Path** field, enter the collection name or cloud storage path where your signals data is stored.
4. In the **Output Path** field, enter the collection name or cloud storage path where you want to store the training data.
5. In the **Category Field in Catalog** field, enter the field name for the category data in your main content.
6. In the **Item ID Field in Catalog** field, enter the field name for the item IDs in your main content.
7. Check that the values of **Item ID Field in Signals** and **Count Field in Signals** match the field names in your signals data.
3. Save the job.
4. Click **Run** > **Start** to run the job.
5. Navigate to **Collections** > **Jobs** > **Add+** > **Classification** to create a new Classification job.
6. Configure the job as follows:
1. In the **Model Deployment Name** field, enter an ID for the new classification model.
2. In the **Training Data Path** field, enter the collection name or cloud storage path from the Build Training Data job’s **Output Path** field.
3. In the **Training Data Format** field, leave the default `solr` value if the **Training Data Path** is a collection or if you used the default format in your Build Training Data job configuration. If you configured the Build Training Data job to output a different format, enter it here.
4. In the **Training collection content field**, enter `query_s`, the default content field name in the Build Training Data job’s output.
5. In the **Training collection class field**, enter `category_s`, the default category field name in the Build Training Data job’s output.